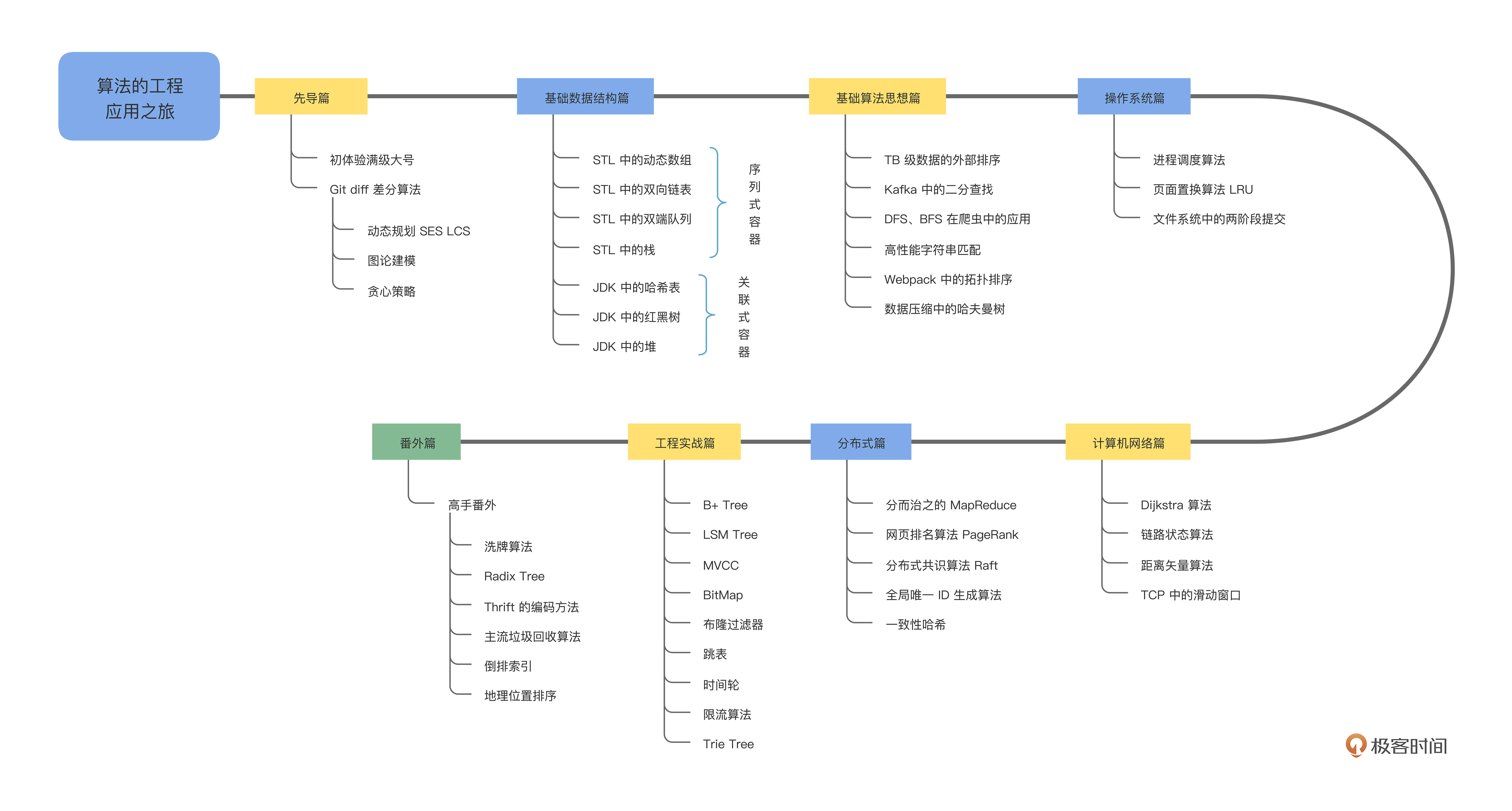
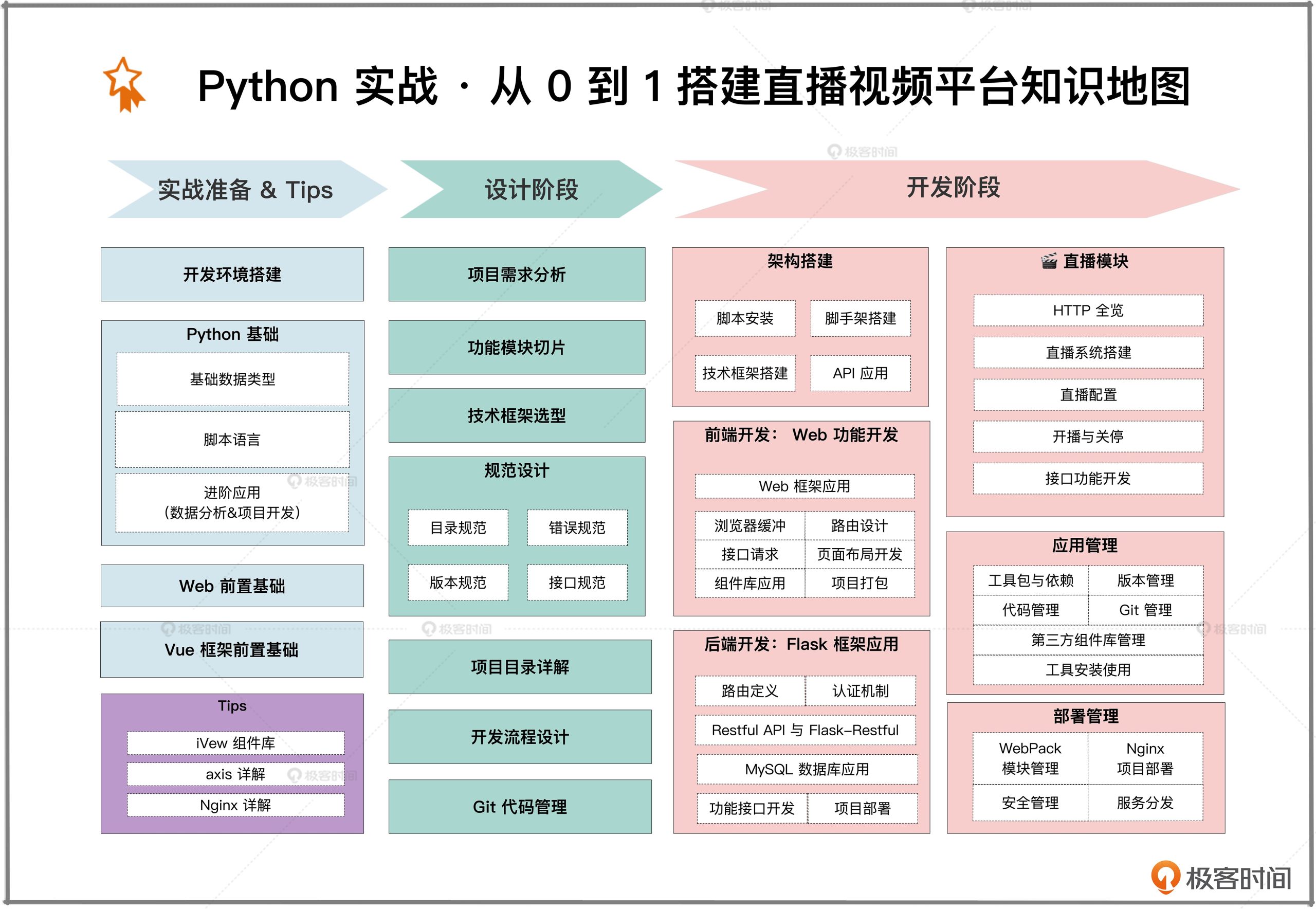
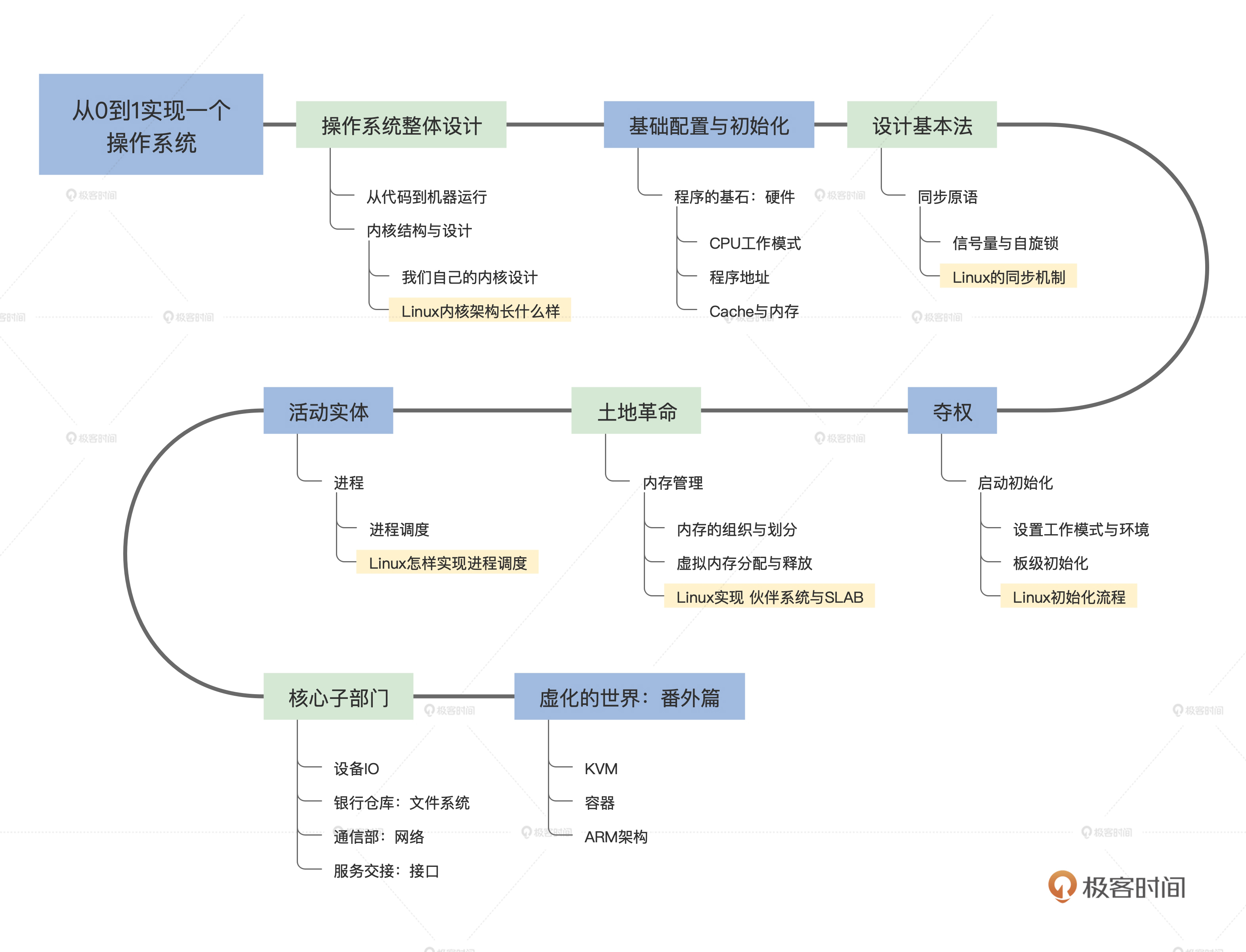
从业务场景出发,搭建监控系统
秦晓辉 快猫星云联合创始人,Open-Falcon、Nightingale、Categraf 核心研发
运维监控系统实战笔记
开始今天分享前,我想先抛一个问题:你觉得哪些人应该学习监控相关的知识?只是运维吗?
其实,每个关注高可用、关注服务稳定性的技术人员都应该学习监控相关的知识。在稳定性保障体系中,核心就是在干一件事,减少故障。我们可以看一下故障的生命周期:
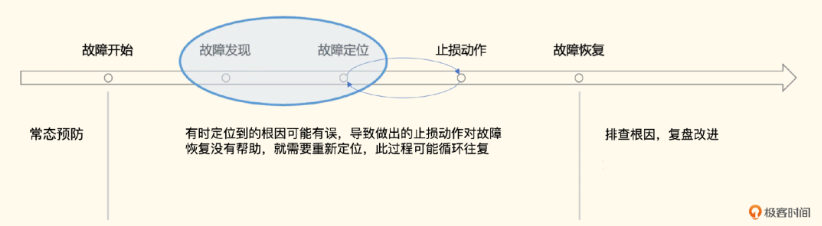
减少故障有两个层面的意思,一个是做好常态预防,不让故障发生;另一个是如果故障发生,要能尽快止损,减少故障时长。而监控的典型作用,就是帮助我们发现及定位故障,这两个环节对于减少故障时长至关重要。
运维人员和研发人员是典型的关注稳定性的人,不过侧重点不同。发生故障的时候,运维人员更希望快速找到问题根因,及时止损。而研发人员,更希望能“自证清白”。不管出于何种目的,监控都是不可或缺的工具。
其实,监控的作用还有很多,比如用于日常巡检,作为性能调优的数据佐证,提前发现一些设备、中间件不合理的配置。 随着时代的发展,监控也从最开始的一句话需求 — 及时感知系统出现的问题,发展到了希望预知问题,并且可以洞察业务经营数据,越来越多的诉求让我们逐渐意识到监控的重要作用。 知道它很重要,但掌握却并不容易。虽然网上可以搜索到很多碎片化的知识,但是都不成体系,很多甚至还有错误。直到前年在朋友圈看到有人分享
「秦晓辉:白话运维监控系统」系列文章,我跟着看下来才找到一些思路。他把晦涩的知识点讲得很通透。 可能有的小伙伴跟我一样,在 Nightingale(夜莺)社区,看过秦晓辉的回答或分享。
他是 Open-Falcon、Nightingale、Categraf 等开源软件的联合创始人和核心研发,多年笔耕不辍,活跃在代码前线。 他拥有 10 余年运维研发经验,曾任职于百度、小米、滴滴等企业,目前在快猫星云合伙创业,为客户提供监控和稳定性保障类产品,对监控和稳定性保障的方法论及实践路径有着深刻的洞见。 昨天看他说运维监控领域,缺少一套体系化的课程,把监控这个事情深入浅出地讲透。
我深有同感,所以当他推出一套系统的、正确的、尽可能完备的运维监控系统知识手册 – 《运维监控系统实战笔记》,我立马就订阅了。 随着前几天课程更新完毕,我也跟着看完了,内容干货满满,且逻辑清晰。
总的来说:课程结合了他在监控领域多年的经验和思考,从基础知识讲起、对比介绍 10 大开源监控方案,带你搭建监控系统,实现业务、应用、组件、资源四大场景的监控需求。推荐大家看看,五六十的价格也不贵,用一顿饭钱来提升自己:
希望你不用像我之前学监控系统那样,为了寻找一个答案而苦苦搜索,再自己去一块一块地拼凑知识。
课程主要分为 4 部分
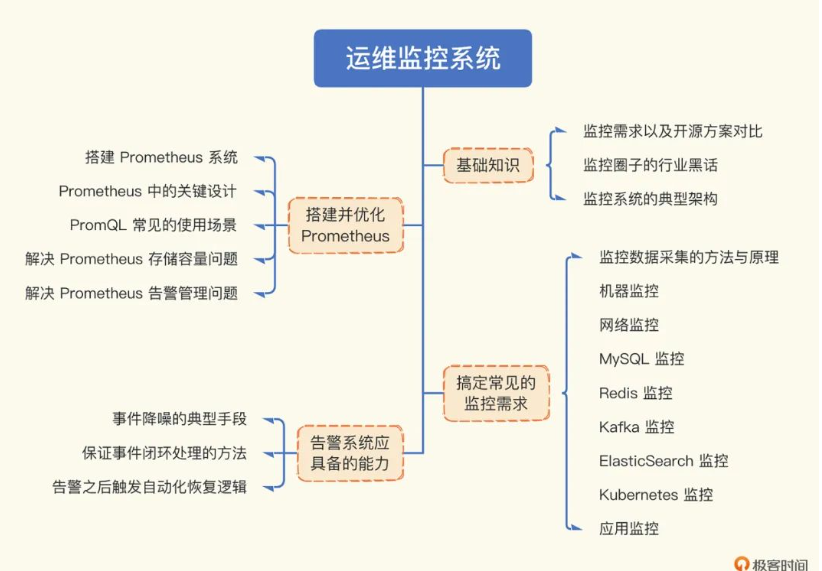
一、基础知识概要介绍 学习监控知识,得先了解为什么,也就是监控是因何产生的,解决了什么问题,有哪些典型的方案,分别有什么优缺点,通用的监控系统架构是怎样的。通过这些内容,我们可以了解监控及相关的概念,为接下来的正式学习打好铺垫。
二、搭建并优化 Prometheus 这个部分他会带我们搭建 Prometheus 这个监控系统,剖析它的关键设计,并给出 Prometheus 薄弱环节的解决方案。让我们有个感性的认识的同时,帮助我们理解监控系统的相关设计。
三、监控实战,搞定常见的监控需求 操作系统、网络设备、MySQL、Redis、Kafka、ElasticSearch、Kubernetes、应用、日志等所有常见监控的需求统统搞定。这个部分会讲解各个监控目标是如何采集监控数据的,有哪些指标最为关键。中间穿插一些问题排查手段,并提供配置好的仪表盘,让你开箱即用的同时,知其然并知其所以然。
四、告警实战,设计良好的告警系统应该具备哪些能力 这个部分的重点就是甄别异常数据并发出告警,包括告警规则、屏蔽规则、抑制规则、订阅规则的管理,还有告警事件的管理以及告警事件触发后的自愈逻辑。 一般监控系统都支持配置告警规则,可以产生告警事件,但是针对告警事件后续的支持偏弱,没有很好的聚合收敛、事件闭环的能力。这个部分主要是为了让你了解告警部分相关的设计逻辑和考量点,帮助你选型这方面的商业产品。当然,如果你后续选择自研,这些思考也会大有裨益。

立即购买
本站内容均为网友上传分享,本站仅负责分类整理,如有任何问题可联系我们(点这里联系)反馈。